The 2017 GBIF Ebbe Nielsen Challenge, which launches today, will award €14,000 in prizes to developers and data scientists who create tools that increase the accessibility and interoperability of biodiversity records available in open data repositories, liberating data for wider scientific discovery and reuse.
The Challenge builds on the growing adoption of open data policies by scientific journals and research funders. To fulfill these rules, researchers have to make the data underlying their findings publicly available and often comply by depositing datasets in public open-access repositories like Dryad and Figshare.
This trend represents a crucial first step toward increasing the openness, transparency and reproducibility of science across all research domains. But in practice, such datasets are not aligned with common standards that ensure the kind of interoperability and reusability envisioned for high-quality open data.
The 2017 Ebbe Nielsen Challenge tasks entrants to develop web applications, scripts or other tools that automate the discovery and extraction of relevant biodiversity data from open data repositories. Such tools would be expected to generate datasets ready for publication on GBIF.org in any of the following ways:
-
Automating searches of open data available in public repositories
-
Effectively mining the information needed to generate checklists, species occurrence and sampling-event datasets (e.g. scientific names, date and location of occurrence et al.) from datasets in these repositories
-
Mapping datasets’ column headings and/or contents with standardized Darwin Core terms
-
Routinely converting the reformatted data into Darwin Core archive formats ready for publication through GBIF.org
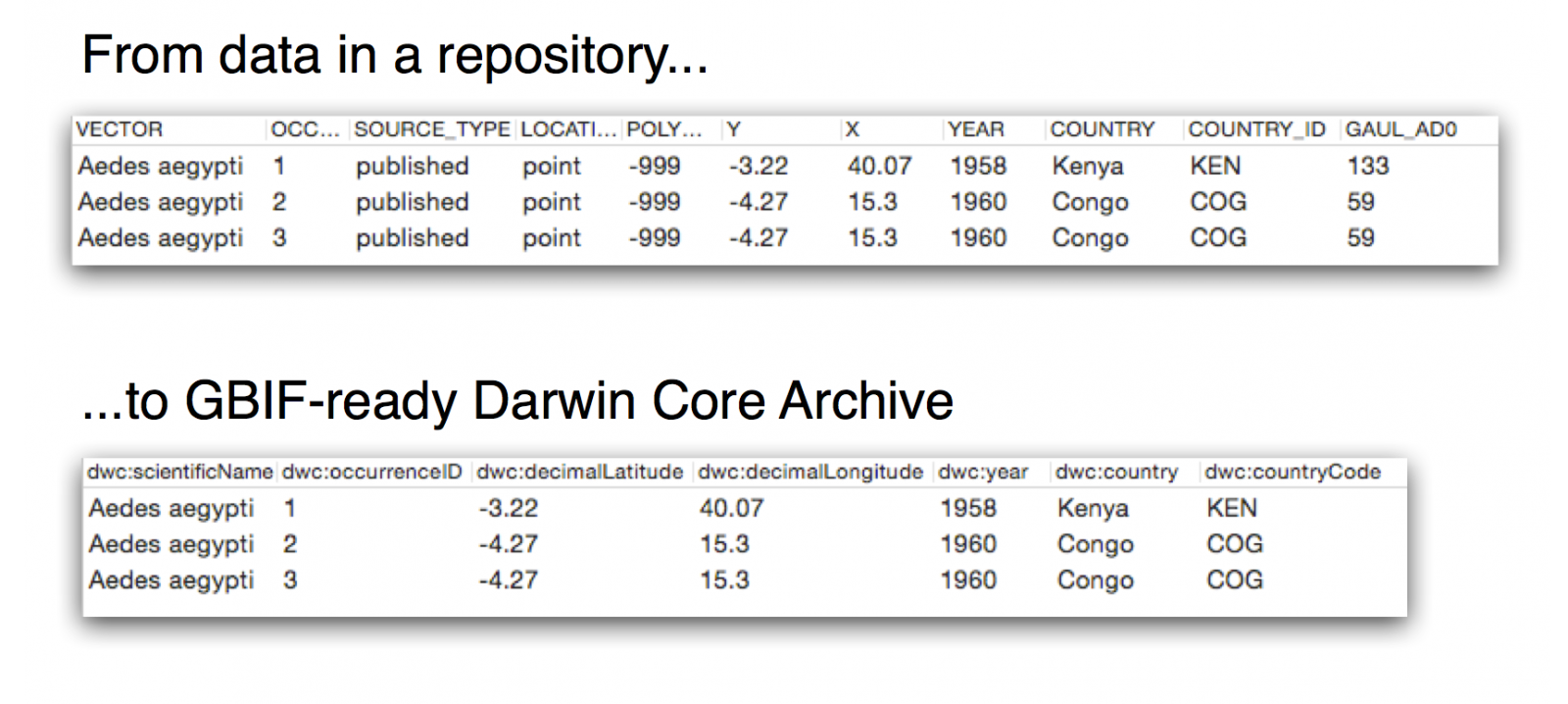
Many of the datasets in public repositories already have a tabular structure and contain the basic information needed to build species occurrence records: scientific names, dates, geographic locations, and quantities, along with other valuable elements that can be standardized. Where datasets are licensed under the CC0, CC BY and CC BY-NC designations used across the GBIF network, they represent suitable candidates for adaptive reuse, republication and sharing (with appropriate attribution) with wider audiences of researchers worldwide.
The Challenge expects submissions will devise processes for preparing these derived datasets into the Darwin Core Archive format (DwC-A) that currently supports the publication of nearly 800 million species occurrence records through GBIF’s international network of nearly 1,000 publishing institutions.
The expert jury assembled for the 2017 Challenge includes:
-
Rod Page, University of Glasgow & chair, GBIF Science Committee
-
Alexandre Antonelli, University of Gothenburg
-
Brenda Daly, SANBI: South African National Biodiversity Institute
-
Rob Guralnick, University of Florida
-
Ana Cláudia Mendes Malhado, Federal University of Alagoas
-
Anabela Plos, GBIF Argentina | Museo Argentino de Ciencias Naturales
-
Amy Zanne, George Washington University
The submission period will run between 15 June and 5 September. Entrants must register all individual team members on DevPost, which hosts all Challenge-related rules and materials. Visit https://gbif2017.devpost.com for complete details and entry requirements.